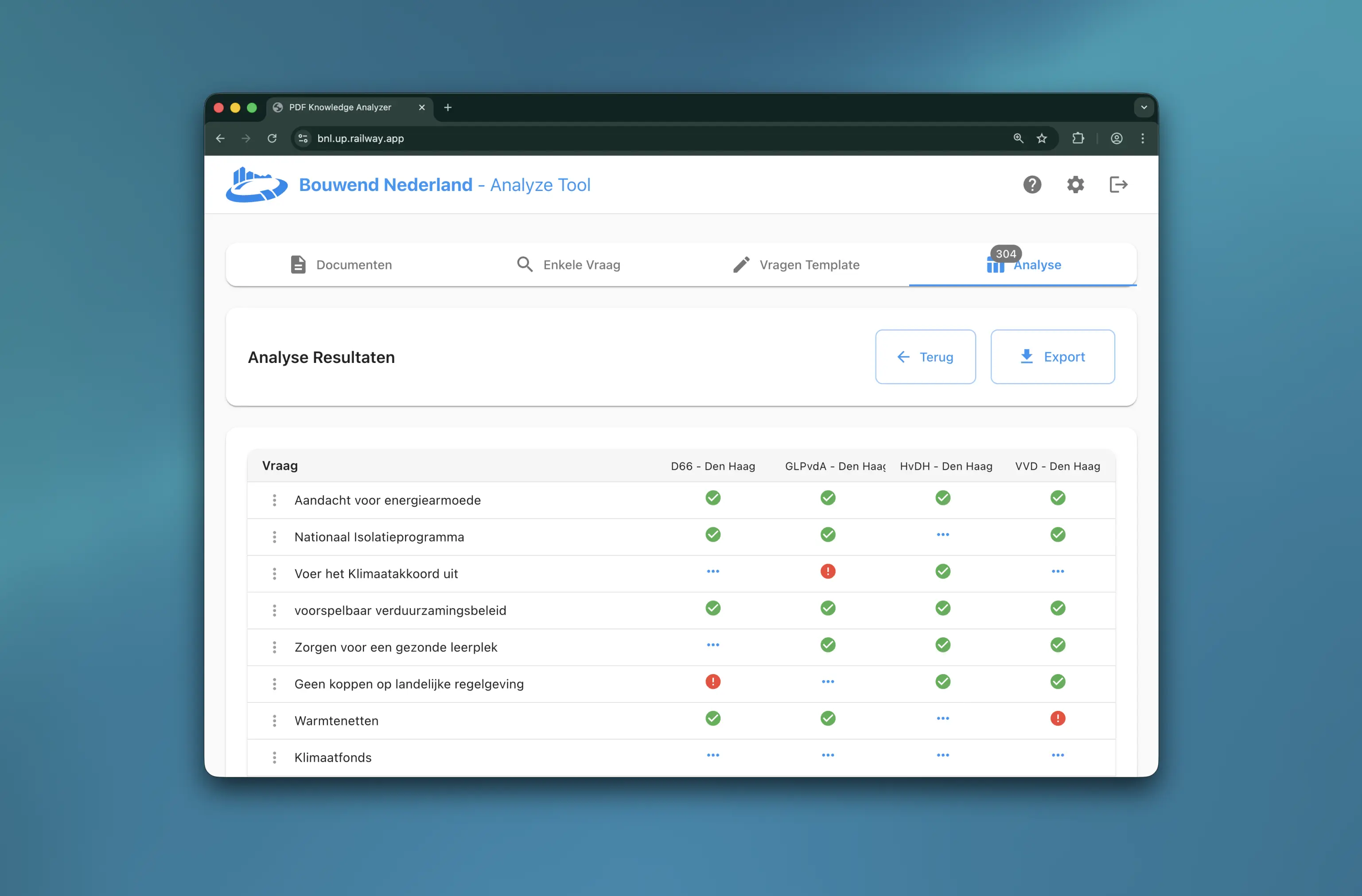
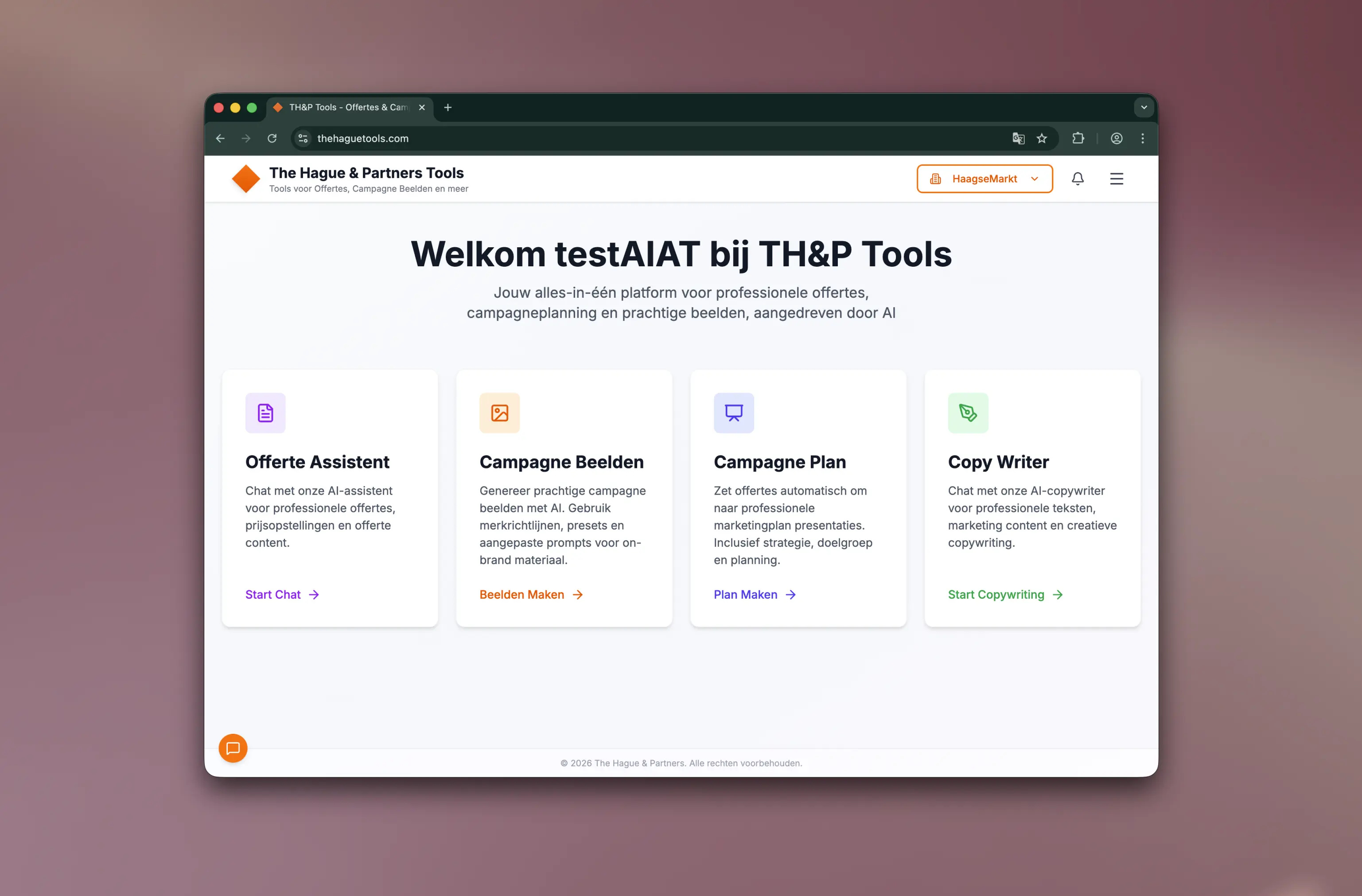
That question gave rise to the Gen-AI Labs: a programme less about broadcasting and more about building. The university set up a safe online environment in which staff could work with language models. Not isolated experiments, but a controlled place where you can learn, test and improve as an organisation. In that environment teams turned ideas into prototypes by writing system prompts and testing iteratively.
The programme consisted of three lab sessions, each with a clear rhythm: sharpen what you build, build and test, and then present with a plan for next steps. We coached teams on grounding, reliability and evaluation: how to make sure answers are based on sources, how to write instructions for language models, and how to let systems work together across multiple steps. This led not only to better results, but also to more trust, because you can explain why an answer is correct and when you should not use it.
Teams also learned to build system prompts, with best practices around role, task, context, constraints, examples and a consistent tone of voice. Structured output was an important part, because many internal processes only really speed up when the output is predictable: think of tables, lists, category choices or formats that can flow straight into a next system. We also helped shape product features around the interaction, such as source references, feedback loops, versioning of prompts, fixed test questions and simple guardrails for users. Those choices make the difference between a nice demo and a prototype that is ready for further development.